Bottom-up creation of data-driven capabilities: show don’t tell
I’ve been writing lately on what to do when people who make decisions in an organization say they want data-driven capabilities but then ignore or attack the results of data-driven analysis for not saying what they think the data ought to say. Some of the most productive things you can do in that situation include automating your work so you can devote more time and attention to more important (and labor-intensive) projects, as well as building support among the organization’s weak actors as a means of garnering positive attention from higher-power stakeholders.
Sooner or later, however, you’re going to have to present actual findings based on actual data to actual stakeholders who could actually make or break your aspirations for building a data-driven organization. These people will probably feel pretty confident that they already know what the data are going to say, and more often than not that confidence will be unwarranted. They will feel unhappy about that.
I’ve faced those sorts of situations frequently in the past. I’ve been told to change data since the findings based on that data “obviously” aren’t right; I’ve been told my analysis can’t be right because it suggests courses of action that aren’t what the organization is already doing; I’ve been told my analysis must just be missing all of the important “unmeasurables” that really determine outcomes; and I’ve been told that the only way I could have arrived at my findings was if I had decided beforehand that those were the findings I wanted.
There’s no general sort of advice anyone could give to address all the ways a stakeholder can choose to undermine confidence in a set of analytic findings. You never know what kind of opposition (if any) you’re going to face until you actually present the findings and take questions. There are, however, ways you can enter into those interactions more prepared to deal with the unexpected. I’ve come to the opinion that the best preemptive measure an analyst can take is to find some way to allow the consumer to take the reins in reaching analytic conclusions. It’s better to get them to decide for themselves that the analysis says something than for me to tell them that’s what the analysis says.
This isn’t just about steering an audience in a certain direction. It’s about building alternative analyses into the presentation. I think the best way to do this is through a user interface that allows a stakeholder to explore whatever options he or she wants instead of just the ones you decided to provide.
For example, I work for a company that sells products and services to educational institutions – mostly to public schools in the United States. Like all companies, we have many more potential customers than we have salespeople, so we need a way to prioritize our marketing and sales activities to devote more attention to customers who are more likely to have the ability and desire to buy our stuff.
Imagine a situation where you had 40,000 schools across six states. You know the grade ranges for each school as well as the median household income for the zip code in which the school is located. Imagine you have enough salespeople to approach all 40,000 schools within a single sales year, but you want the salespeople to devote more time to schools that are more likely to purchase. Also, imagine you have sales managers who are extremely averse to any data-driven (read: complicated-looking) prioritization. They want to be able to give their sales people four categories of schools and tell them to spend more time on category 1 than on category 2, more time on category 2 than on category 3, etc.
Here’s one way to address this problem: the different states (say, California, Washington, Oregon, Arizona, Nevada, and Utah) already constitute convenient analytic categories. The lowest grade offered at a school (say, kindergarten, 1st, 5th, 7th, and 9th) and the highest grade (say 5th ,6th ,8th ,9th , and 12th) make up some additional categories. Take the median income and divide it into, say, ten subdivisions. Theoretically, there are 1,500 different combinations of the state, low grade, high grade, and income categories. There are different numbers of schools that match each combination, and, presumably, any company would have sales records for any schools that purchased in the past.
So go through each of those 1,500 micro-segments and figure out the total amount of revenue generated, the average amount of revenue generated, and the total number of schools in the division. Total revenue gives you an estimate of how profitable a micro-segment is. Average revenue gives you an estimate of how easy it will be to sell to a school in that micro-segment (schools that show zero revenue will pull down the average in micro-segments that have many such schools).
You can now compare the average revenue and total revenue for each of those micro-segments to create four categories:
- More profitable and less difficult to sell
- More profitable but more difficult to sell
- Less profitable but less difficult to sell
- Less profitable and more difficult to sell
You can divide the more from the less just by taking the above-median and below-median micro-segments. Or you can fit a linear model and separate the micro-segments above and below the fit line. The point is you’ll end up with a segmentation that takes all 1,500 combinations of variables into account instead of the conceptually simpler “we want high-income elementary schools in the Pacific Northwest.”
So you have some analytic findings. Great. Suppose the managers who requested the analysis really do think they just want high-income elementary schools in the Pacific Northwest. Telling them that the analysis says differently might not impress them. This is where an interactive analysis comes in helpful:
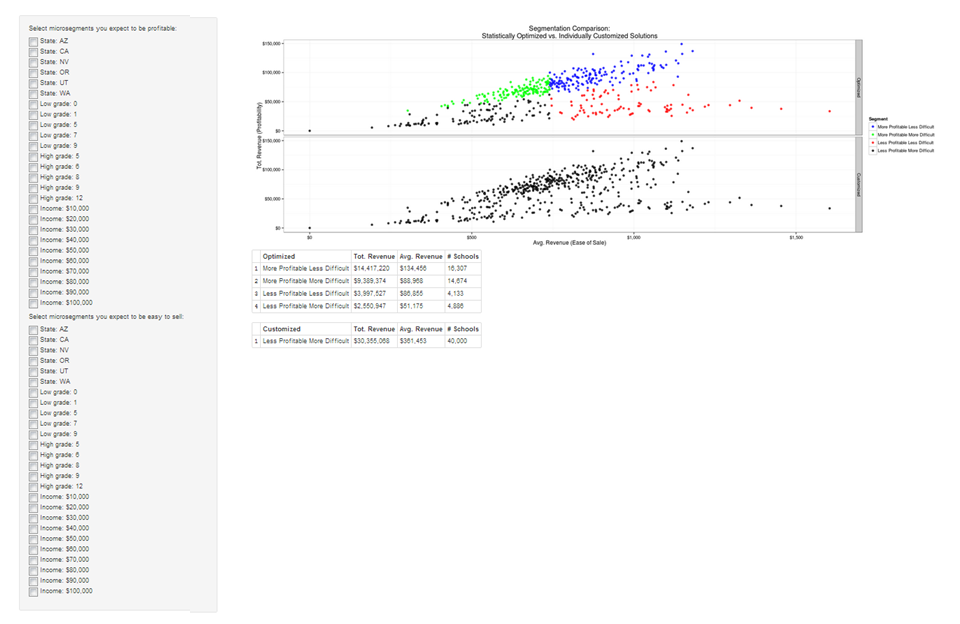
Click on the image to see the interactive version (if the link in the image doesn’t work, go to http://glimmer.rstudio.com/schaunwheeler/SegmentViewer/). The top facet of the graph plots the micro-segments by average revenue and total revenue, and color-codes them by which of the four segments they fall into. The lower facet plots the same metrics but color-code them by where the segmentation assignments fall if they are made by hand – a manager could check off the boxes on the left-hand side to indicate which values he or she thought were more likely to correspond to profitability or relatively easy sales. The graph automatically updates to allow comparison of those intuitive categories to the categories that are based fully on the data, and the tables provide some summary measures for reinforcement.
Just to be absolutely clear: nothing in the linked application uses actual data from my employer. I created the data by randomly drawing from different categories for each variable. The code for doing so can be found through the link at the bottom of this post.
Experiment with the application by clicking around. There are no choices you can make that won’t result in loads of undesirable exceptions – high-total, high-mean micro-segments categorized as Less Profitable and More Difficult, or obviously low performers categorized as being desirable. That’s not because I built this app to only show what I wanted it to show. It’s because comparisons of means and sums provide a much finer-grained categorization method than does the broad application of more intuitive categories. You could choose whatever metrics you wanted instead of sums and means, and you could divide them into categories using much more sophisticated procedures than medians and linear models. The point is that, however, you decide to do the analysis, the consumer ought to be able to play with the results.
I’m not saying an interactive presentation of results will break down all the opposition to data-driven analysis in an organization. What it does is make the consumption of analytic results a communication-based activity instead of a presentation-based one. It allows consumers to see the direct consequences of their choices, whereas most managers and executives I’ve known have only ever seen the indirect consequences of those choices. They decide to go with their intuitive categories instead of a rigorous analysis, and then are angry a year later when sales aren’t where they’d like them to be. In most cases, those decision makers had never been in a situation where they could clearly see all the missed opportunities and wasted energy that would necessarily result from the application of the oversimplified rules and categories they were advocating. Interactive results address that specific problem, which is, I think, a good place to start.
Note:
You can find the full code for the app at https://gist.github.com/4207354. I used RStudio’s `shiny` application, the documentation for which can be found here. It’s still in the fairly early stages of development – for example, I don’t think there is currently any way I could have divided the profitability and ease of sales sections of the sidebar into state, low grade, high grade, and income subsections, and no way I could have placed the profitability and ease of sales sections side-by-side. But it’s crazy easy to use and I expect the R community to really jump into developing this one. I’m kind of excited about all the ways people are developing methods for R to do things outside of the R console.
If you want to comment on this post, write it up somewhere public and let us know - we'll join in. If you have a question, please email the author at schaun.wheeler@gmail.com.